Model Evaluation (모델 평가)
예측을위한 feature와 알고리즘 등을 정리하여 Machine Learning 모델을 만들었다면,
이 모델이 제대로 만들어진 것인지, 어느정도 예측력을 발휘할지 확인을 해봐야 합니다.
이번 포스팅에서는 모델을 평가하기 위한 훈련 방식에대해 살펴보겠습니다.
train_test_split
우리가 가진 데이터가 100개 라고 가정한다면,
70개의 데이터를 사용해서 모델을 만들어보고
나머지 30개의 데이터는 결과값을 모의 예측하는데 사용하는겁니다.
scikit-learn에서는 train_test_split이라는 함수를 제공하여 아래와 같이 간단하게 나눌 수 있습니다.
from sklearn.model_selection import train_test_split
train_data, test_data, train_label, test_label = train_test_split(X_train_data, X_train_label, test_size = 0.3, random_state=0)X_train_data : 독립변수
X_train_label : 종속변수
test_size : test data의 비율 (0.3이라면 30%를 의미하며 default 값은 0.25입니다.)
random_state : random seed 번호
train_data , test_data : training set
train_label , test_label : testing set
K-fold cross validation
cross validation, 교차검증(CV) 이라고합니다.
K-fold cross validation은 데이터를 K개의 fold로 나누어 여러번 검증하는 것입니다.
우리가 앞서 100개의 데이터를 이용하여
1번~70번까지의 데이터로 훈련데이터를 만들고, 71번~100번 데이터로 검증데이터를 만들어 모델 평가를 1회 진행했다면,
K-fold 교차검증방법을 이용해 5회 fold를 만들어 진행하는 경우에는
1~20 : 검증데이터, 21~100: 훈련데이터 -> 1회 훈련
21~40 : 검증데이터, 그 외 훈련데이터 -> 2회 훈련
41~60 : 검증데이터, 그 외 훈련데이터 -> 3회 훈련
71~80 : 검증데이터, 그 외 훈련데이터 -> 4회 훈련
81~100 : 검증데이터, 그 외 훈련데이터 -> 5회 훈련 처럼 여러차례 검증해보는 방식입니다.
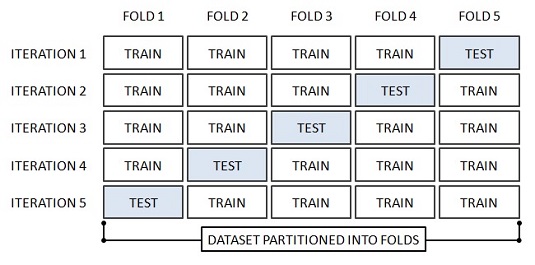
<이미지 출처 : https://www.dummies.com/programming/big-data/data-science/resorting-cross-validation-machine-learning/>
교차검증의 경우, 연산이 몇 배로 늘어난다는 단점이 있지만
데이터의 수가 충분하지 않은 경우 underfitting도 예방할 수 있으며
랜덤하게 데이터를 나누어 1회만 검증 할 경우, 나누어진 데이터의 구성에 따라
(우연찮게 예측하기 쉬운 데이터들이과 그렇지 않은 데이터들로 나누어졌다거나..)
높거나 낮은 예측률을 발휘하는 등의 상황을 예방할 수 있습니다.
>>> from sklearn.model_selection import KFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([1, 2, 3, 4])
>>> kf = KFold(n_splits=2)
>>> kf.get_n_splits(X)
2
>>> print(kf)
KFold(n_splits=2, random_state=None, shuffle=False)
>>> for train_index, test_index in kf.split(X):
... print("TRAIN:", train_index, "TEST:", test_index)
... X_train, X_test = X[train_index], X[test_index]
... y_train, y_test = y[train_index], y[test_index]
TRAIN: [2 3] TEST: [0 1]
TRAIN: [0 1] TEST: [2 3]<scikit learn 홈페이지 : https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html>