안녕하세요.
이전 포스팅에서 모델평가를 위한 훈련방식을 알아봤다면,
이번 방식에는 모델평가를 위한 채점방식,
즉 이 모델이 얼마나 예측률을 가지는지를 점수로써 환산하는 방법을 알아보겠습니다.
분류방법이 Classification이냐, Regression이냐 에 따라 평가방식이 다른데요.
이번시간에는 Classification인 경우로 알아보겠습니다.
Classification에는 일반적으로 아래와 같이 3가지 채점방식을 사용하며, 각각 알아보겠습니다.
1.Jaccard Index
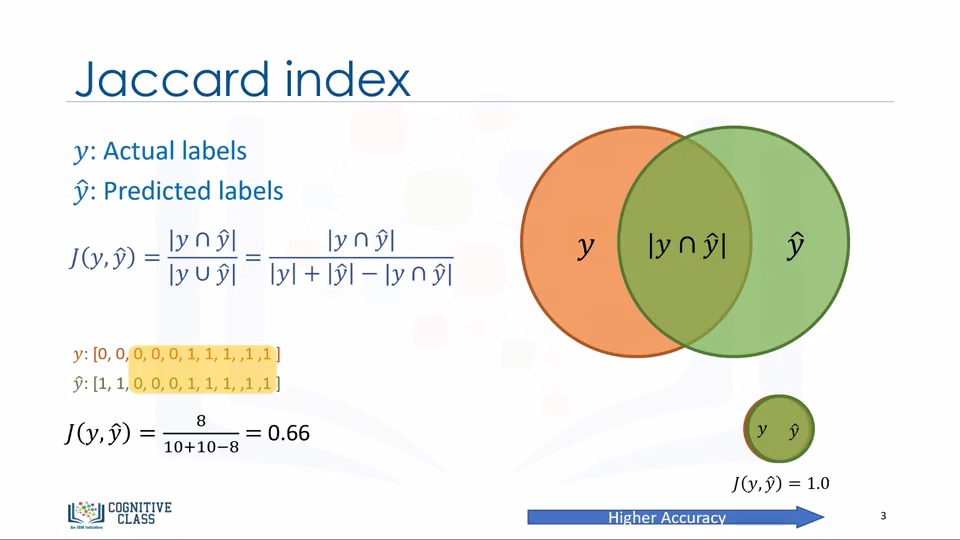
간단하게 이야기하자면 정답률 입니다.
정답갯수 / X레이블갯수 + Y레이블갯수 - 정답갯수
0~1의 값으로 1에 가까울수록 좋은 모델입니다.
2.Log-loss
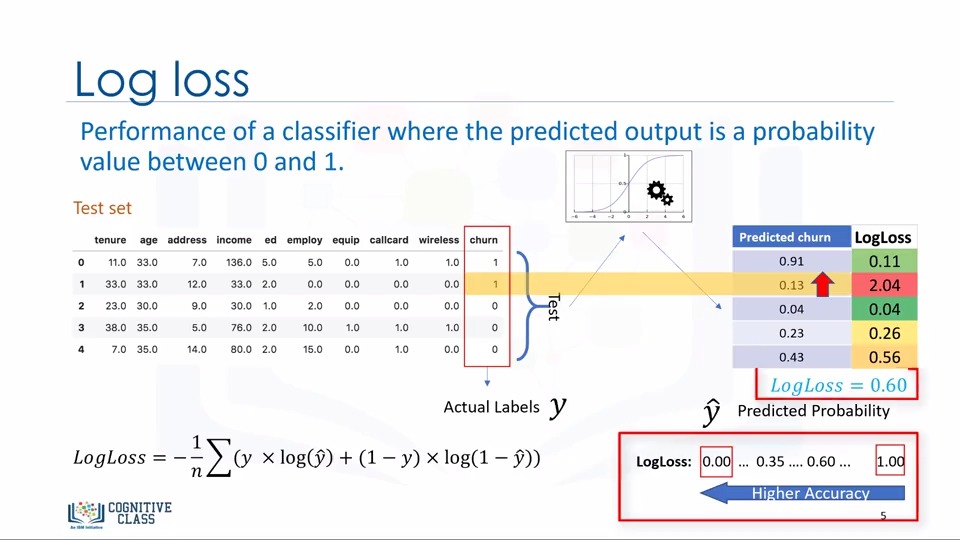
Logarithmic loss이라고 합니다.
예측값의 확률을 가지고 오차를 계산합니다.
0~1의 값으로 0에 가까울수록 좋은 모델입니다.
3.Confusion matrix

Confusion Matrix, 오분류표라고 합니다.
여기서는 값의 비중이 너무 치우쳐지는 것을 방지하기 위하여 F1-Score(정확도와 정밀도의 평균)를 사용하고,
0~1의 값으로 1에 가까울수록 좋은 모델입니다.
- confusion matrix 개념정리
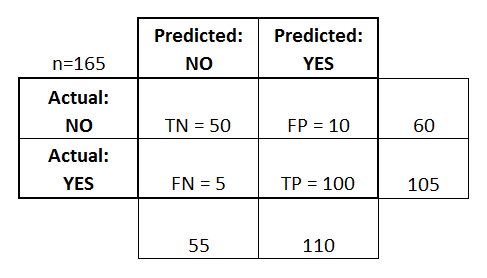
<이미지 출처 : https://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/>
true positives (TP): Yes로 예상했고 실제 값 또한 Yes로 제대로 분류한 경우.
true negatives (TN): No로 예상했고 실제 값 또한 No로 제대로 분류한 경우.
false positives (FP): Positive로 예상했지만 실제 값이 No로 오분류한 경우. (1종오류)
false negatives (FN): No로 예상했지만 실제 값이 Yes로 오분류한 경우. (2종오류)
Accuracy : 정분류율 (TP+TN)/total = (100+50)/165 = 0.91
Misclassification Rate : 오분류율 (FP+FN)/total = (10+5)/165 = 0.09 (= 1-Accuray)
True Positive Rate (“Sensitivity” or “Recall”) : 실제 Yes인 값들 중 Yes로 예측한 비율 (민감도 혹은 재현률)
TP/actual yes = 100/105 = 0.95
False Positive Rate: 실제로 No인 값들을 Yes로 예상한 비율
FP/actual no = 10/60 = 0.17
True Negative Rate (“Specificity”) : 실제로 No인 값들 중 No로 예측한 비율 (특이도)
TN/actual no = 50/60 = 0.83 (=1-False positie rate)
Precision: Yes로 예측한 값들 중 실제로 Yes인 비율 (정밀도)
TP/predicted yes = 100/110 = 0.91
Prevalence: 전체 데이터 중 Yes의 값이 얼마나 많이 일어났는가
actual yes/total = 105/165 = 0.64